Lessons from a small Firebase project.
Awesome in principle, more painful in practice — there are some big gotchas waiting for the intrepid developer.
After hearing all the good things about Google Firebase for a while, finally I got to use it last week. I’m building a really simple solution for a client that provides some basic functionality:
- Anonymous users provide feedback on a mobile device, including uploading photos.
- Supervisors (authenticated users) view this feedback on a real time web dashboard on a PC somewhere.
This isn’t particularly hard in any development environment you choose, but I’m doing everything in serverless in 2018 and there are two items that are harder than they look — authentication and real time data. Firebase is famous for both of these so I take it for a spin.
Firebase: A great start.
Signing up for Firebase is brainlessly easy and within seconds you’re staring at a highly intuitive dashboard that’s much nicer than either the AWS or Google Cloud Platform equivalent.
You’ll also be wowed at Firebase’s excellent documentation and quickstart information, and have a fully working demo app running in about 30 minutes.
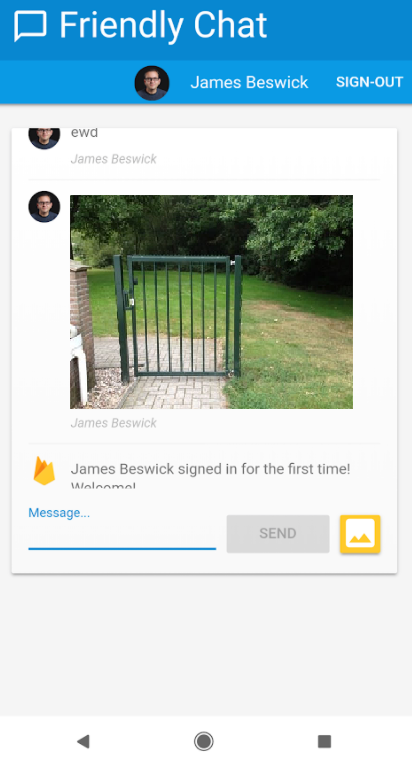
At first glance the Friendly Chat web app is about 70% of what I need to build so I’m at the Early Euphoria phase of the project, where developers mistake a small success for the entire victory. This is a slick app — you can post messages and photos, they upload and appear on every client instantly and — boom! — another win for the cloud.
What you quickly learn about the Firebase approach is that everything happens on the client — all your logic lives in JS files that are statically hosted by Google and it automagically syncs, with all the authentication and complexity handled for you. Looking through the Friendly Chat app, the code is beautifully easy to read and understand:
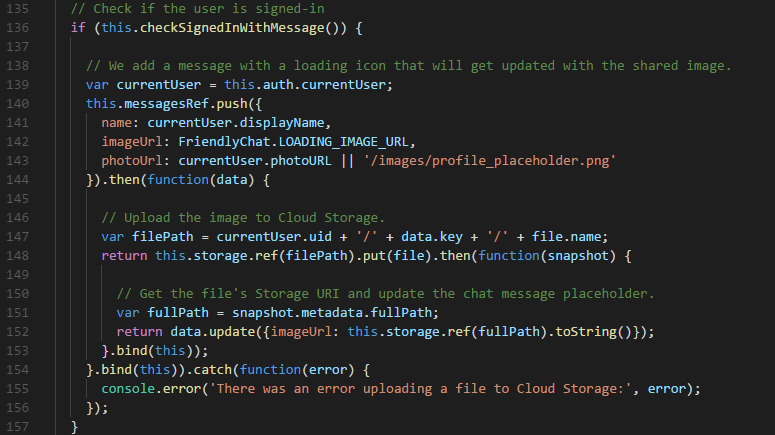
When I read JavaScript from Google’s engineers, it’s like looking at a painting from an old master: it’s an elegantly structured beautifully reductive thing, whereas my own code is more like a stick-figure I doodled on the back of a McDonald’s napkin. Maybe I code pretty some day but with this much assistance from a modern-day Matisse, I should be done with this project today, right?
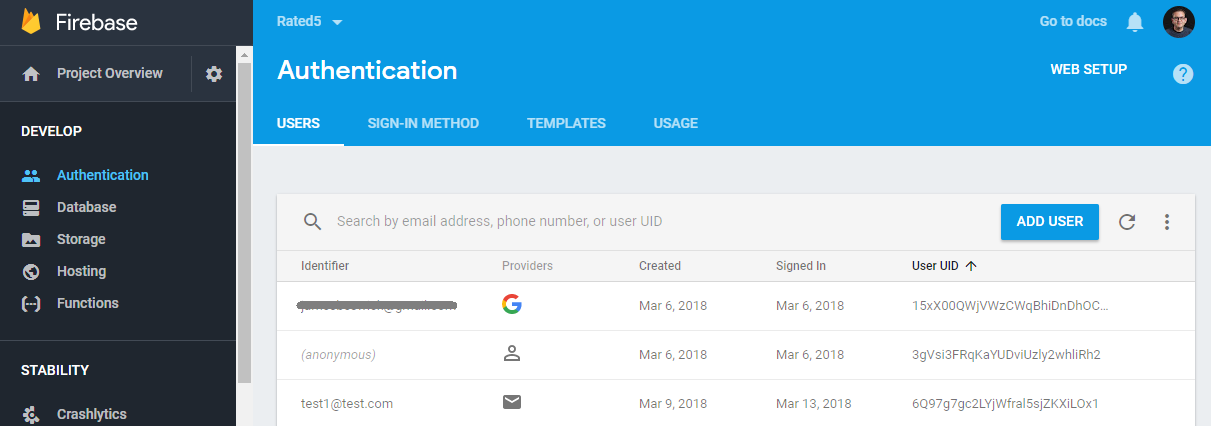
Firebase auth: drop-in ready but barebones.
One of the biggest reasons I started down the Firebase path was user authentication. Auth is a monumental recurring pain that haunts projects. You need it everywhere in mobile and web apps and it’s simultaneously dull and terrifying — it never does anything new or interesting but if you screw it up, your entire world is engulfed in flames as bots or foreign hackers steal everything you ever owned.
AWS has Cognito — which I almost love but has a steep learning curve mired by inconsistent documentation that was originally intended for mobile developers. The Cognito JS docs are morphing into something called AWS Amplify and there isn’t a complete example anywhere of how to use Cognito on NodeJS statelessly in serverless. This in-between state makes it fairly difficult to figure out and every Cognito tutorial I’ve even seen is like this:

Compare that with the promise of Firebase which offers Google-grade drop-in authentication that ‘just works’.
Within an hour I’ve cobbled together my fully-functioning auth — but it’s not quite what I expected. In the Firebase-provided UI, there’s no way to prevent new user sign-ups. And it’s also soon obvious that Firebase doesn’t do anything around authorization, so you have a crowd of users with no easy way to split them into end-users and admins.
I rip out the drop-in UI and code my own — it solves the ‘new user’ problem. I then create a users table to track what each user is allowed to do. Firebase auth also doesn’t let you store any temporary data. Cognito by comparison does let you manage authorization and store some data and by the time I’m finished, probably isn’t much more work.
Real-time database and Firestore.
One of the main selling points of Firebase is the real-time database. It’s a managed NoSQL database with a pub-sub wrapper — put simply, you change data and any front-end will instantly update with the new document with about a dozen lines of code. This is a total slam dunk for shopping carts, chat apps and anything else where changing state can happen on multiple devices in real time. Go, Google go.
Better yet, it seems to do things that DynamoDB won’t — you can sling around JSON documents with ease, understand the data types without your head exploding, and it even has a handy location datatype for latitude/longitude storage. Adding real-time notifications to a DynamoDB isn’t trivial — you’re looking at Lambda triggers, IoT integration and web sockets.
Well, Firebase database is actually two products under the hood, the second being Firestore, which their documentation heavily sells for new projects. Firestore is based on Datastore and offers shallow queries in nested documents, automatic scaling (no sharding knowledge needed), batch operations and features that will make you want to leave DynamoDB yesterday. However, the API is slightly different all over the place so it’s not a instant replacement for Firebase DB, and you’ll have to rewrite any code that was using RTDB.
Before committing too quickly, here’s the real gotcha: Firestore is in beta. You could wake up one morning and find your application’s database is no longer supported by Google. I’ve learned the hard way to never put Google’s beta products anywhere near production, given their Wheel of Fortune approach to product retirement. Compared with Firestore, Realtime DB has been around a for a while but is slim on features by comparison.
It’s also worth knowing that there’s no import/export feature for your Firestore data yet — Google is ‘working on it’ though.
The limits of all client, no server.
Although I like the idea of shoving everything in the JS file on the client, my sense of social responsibility won’t let me. For instance:
- I have lookup tables that contain a list of every client’s end customer. I want the user to lookup individual locations but not expose the entire thing.
- I need to add documents to the database but don’t want to blindly spew data into the collection without doing some sanity checking first. And if this check happens in the client browser, it may as well not happen at all since malicious users can change code here.
Clearly we’re going to need some serverless goodness, which is Cloud Functions in Google speak. I can roll up a CRUD API that handles these problems easily, hiding the actual code from potential bad actors. Better yet, I find that http triggers on Cloud Functions are really handled by Express in the background so it seems like a quick win to pull this off.
Before long, I start coding up Cloud Functions for all sorts of things, mainly to avoid the spaghetti code of JavaScript on the front end, but also because it seems just wrong doing so much backend manipulation in plain sight of the end user. I build out a serverless middle layer. After using Lambda so dependably in the past, this seems like a logical step and didn’t even imagine the next problem it would cause.

Cold starts are more like “Thaw from frozen”.
If you come from AWS, you’re used to fast execution on Lambda. Most of my code is mundane do-this-do-that kind of stuff, but I’m accustomed to getting in-and-out of Lambda in 100ms. Sometimes 200ms. Rarely 300ms.
Because AWS sets the bar so high for itself, we all lost of minds when we discovered the “cold start”. This is when your function hasn’t been used for a while so Lambda puts it to bed. You unexpectedly call the function again and Lambda has to wake it up, get it dressed and send it off to work without breakfast. Chaos ensues. Instead of taking 200ms, now it takes 400ms on the first invocation and you see ops experts making graphs like this:
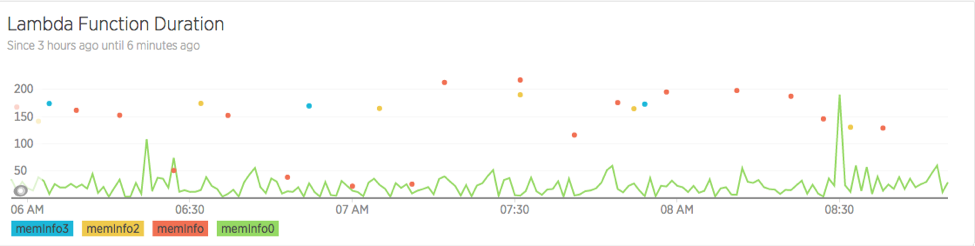
“How dare Amazon not keep all my functions in memory all the time?” we demanded. Well, my fellow cloud enthusiast, I have news for you — we’ve had it so good on Lambda. We have been complaining about 40 degree weather when a Firebase cold start is more like Siberian permafrost:
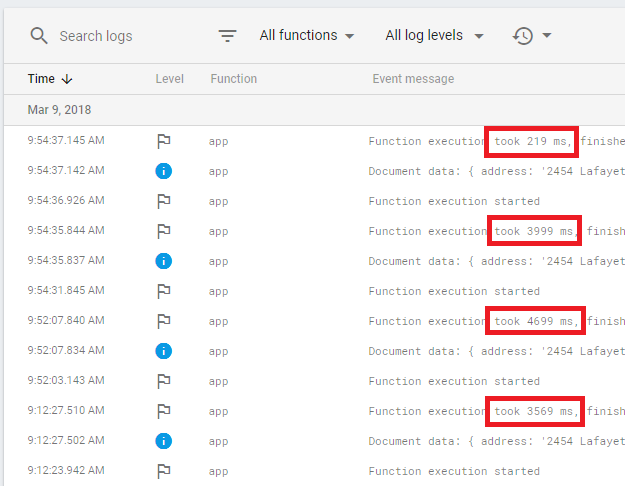
Firebase cold starts seem to happen all the time. If you don’t use a function for few minutes, you can expect a cold start. I tested this with a simply global variable console.log and it’s clear that you are starting over very often.
Even testing a boiler-plate “hello world” Firebase Cloud Function , the execution times vary wildly. With no libraries to load or anything else, I see times from 60ms (yay) to 500ms (wtf?).
After some more Googling, I discover I’m not the only person to complain about the pitiful performance of Firebase’s cloud functions. I can live with anything under a second to be honest — but in my testing I routinely experienced 4–5 seconds and a few times up to 20 seconds. That’s simply not acceptable for anything production-level.
I put this out on StackOverflow and while a Google engineer responded very quickly, it sounds like slow Firestore/Cloud Functions integration is a general issue for now: “Bear in mind that both Cloud Functions and Cloud Firestore are both in beta and provide no guarantees for performance.”
Inconsistent deploys.
One evening I did a firebase deploy --only functions and it deployed successfully. The next morning, I accidentally up-arrowed in my terminal and and ran the same command — no problem, I’ll just wait for it to deploy exactly the same code. I wait, and wait and wait…
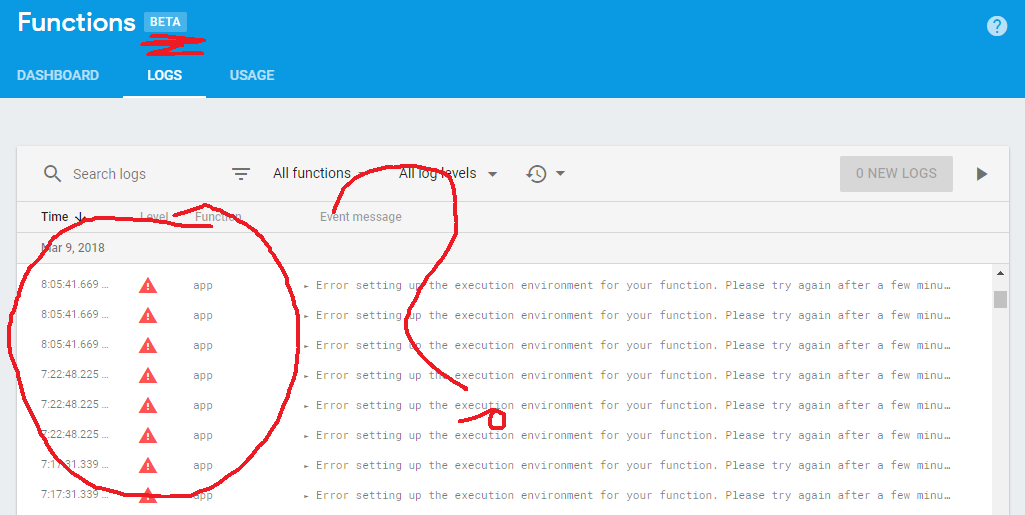
I try several more times and each time the deployment times out. Frantically searching Stack Overflow, I’m clearly not the first person to encounter these problems and there are a couple of alarming solutions:
- Rename your functions and deploy again (wtf?)
- Wait a while and try again.
The logs tell me really nothing and then once again I notice the dreaded “Beta” label on Cloud Functions. Oh dear. An hour later, I do the same deploy and it worked just fine. Call me old-fashioned but I like my deployments just like my coffee — the same every single time. In subsequent deployments it occasionally hangs in the command line, leaving you with no idea at all if it deployed or not.
Here’s another weird one: getting around CORS problems involves some well-trodden usage of the Express CORS package in NPM. Everything here was working too until I upgraded the firebase-tools package on my dev machine and then suddenly http requests started failing preflight requests — with no change in my code.

Overall, Firebase feels more like ‘Firebeta’.
For a demo app, Firebase sings like Beyoncé; for anything more complicated, it sounds more like Pierce Brosnan.
Firebase originated from a chat platform called Envolve, which was bought by Google and Frankenstein’d into a broader product. While that single product works quite well — namely, pushing real-time data to-and-from a database table — I found significant problems when building out everything else.
Over the last few months I’ve become very comfortable with a development setup that includes Serverless, Lambda, Auth0, API Gateway and DynamoDB. I still struggle with DynamoDB at times but in terms of performance AWS is absolutely solid. Also, Auth0 is the simplest auth product I’ve found anywhere and continues to work well in any development environment you choose.
It may be that Firebase solves these issues over time but the combination of deployment failures, slow function execution and major parts still in beta means it not a viable option for me. Ultimately in this case I found I could use a single real-time DB in Firebase and run everything else from AWS — remarkably this worked just fine.