Scanned Numbers Recognition using k-Nearest Neighbor (k-NN)







Tags: Python, scikit-image, scikit-learn, Machine Learning, OpenCV, ImageMagick, Histogram of Oriented Gradients (HOG).
How to extract the numbers printed on 500 scanned images with noisy background (as shown below) into an excel file with 100% accuracy in 2 minutes?
The simple answer: you can’t in 2 minutes, it takes 8 minutes to attain 100% accuracy.
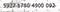

It takes 2 minutes to pre-process the images and for a Machine Learning model to correctly predict 98% of the digits and 6 minutes for a person to manually fix the 2% inaccurate prediction, albeit with minimal effort. The 6 minutes was made possible by presenting to the user the digits that the model was unable to classify with 100% confidence as shown in the “Presentation” section at the end of this blog.
Unsuccessful Approaches
Before explaining the k-NN solution, I’ll briefly go over some of the unsuccessful methods I’ve explored to extract the digits.
1- Tesseract — Google’s Optical Character Recognition (OCR)
Applying Google’s Tesseract resulted in low accurate digits recognition despite using Tesseract’s options to recognize an image as a single text line and to OCR digits only. Note that the images background noise were removed before applying Tesseract (more on the de-noising step later in this blog).
2- Image Template Matching
The second approach was to produce template images for each of the 9 digits and then detect each digit in an image and compare it to each of the 0 to 9 templates using openCV’s matchTemplate function
import cv2result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
This approach did not work for our problem due to noise. However, this blog https://www.pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/ successfully demonstrates the use of template matching to recognize printed digits on credit cards.
Successful Approach: Training and Predicting using Machine Learning
The last approach was to train my own Machine Learning model. This solution required the following:
- Singling out each digit from an image
- Choosing appropriate feature extraction to apply on each digit
- Choosing a multi-class classifier
Input/data pre-processing, feature engineering, and data preparation lie at the heart of any Machine Learning based solution. The choice of which Machine Learning classifier to use is an important step, however, its success lies in the above mentioned.
Outline:
- Image Pre-Processing
- Digits Extraction and Training / Testing Data Preperation
- Feature Extraction
- Training
- Predicting
- Presentation
1. Image Pre-Processing
TextCleaner script by Fred Weinhaus (http://www.fmwconcepts.com/imagemagick/textcleaner/) has been used to remove the image background noise followed by an image sharpening step. Both these steps require ImageMagick library (https://www.imagemagick.org). Alternatively, I recommend using python’s libraries such as OpenCV or scikit-image to pre-process the images.
# text cleaner
./textcleaner -g -e stretch -f 25 -o 10 -u -s 1 -T -p 10 input.jpg output_clean.jpg# image sharpening
convert output_clean.jpg -sharpen 0x10 output_sharp.jpg
The above code resulted in the following image

2. Digits Extraction and Data Preperation
Singling out each digits from an image using OpenCV’s findContour operation did not produce reliable results due to noise. For this specific problem, it was more robust to detect the “bounding box” arround the digits (image cropping) and then “single out” each digit out of the cropped image. The latter step is easy after finding the bounding box since each digit will have a fixed coordinates relative to the upper-left corner of the cropped image.

Note: Black / White pixels were inverted needed for feature extraction using Histogram of Oriented Gradient (HOG).
2.1 Detecting the Bounding Box
Using third party tools to crop the boundaries of the images did not work well on all images. Instead, I created a simple method to deterministically crop the images and detect the bounding box with 100% accuracy.
The method starts by counting the white pixels of a rectangle as shown in Figure 4. If the count of white pixels exceeds an empirically set value, then the coordinates of the rectangle are the upper boundary of the digits and will be used to crop the image.




The same technique can be used to left crop the image as shown in Figure 6.


The output of the above operations resulted in the following imag:


2.2 Digit Extraction
Now that the bounding box is detected, it should be easy to single out each digit since each digit will have pre-fixed coordinates relative to the top-left corner of the cropped image.
I’ve applied the above code on a set of images and manually sorted the images of each digit into separate folders labeled from 0 to 9 as shown below to create my training / testing dataset.


3. Feature Extraction
Feature extraction or feature engineering is the process of identifying the unique characteristics of an input (digit in our case) to enables a Machine Learning algorithm work (in our case, to cluster similar digits). Of particular interest is the Histogram of Oriented Gradients (HOG) which has been successfully used in many OCR applications to extract handwritten text. The following code illustrates extracting HOG from an image using skimage’s hog function.
from skimage.feature import hogdf= hog(training_digit_image, orientations=8, pixels_per_cell=(10,10), cells_per_block=(5, 5))
In my case, the image is 50x50 pixels and hog’s input parameters (i.e. pixels_per_cell and cells_per_block) were empirically set. The figure below illustrates applying HOG on an image producing a vector of 200 values (i.e. features).


4. Training
In the previous steps, we extracted similar digits into folders to build our training dataset. The code below illustrates building our training / test dataset.
Now that we created the training dataset and stored it into features and features_label arrays, we then divided our training sets into training and test sets using sklearn’s function train_test_split and used the result to train a k-NN classifier and finally saved the model as illustrated in the code below.
# store features array into a numpy array
features = np.array(features_list, 'float64')# split the labled dataset into training / test sets
X_train, X_test, y_train, y_test = train_test_split(features, features_label)# train using K-NN
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)# get the model accuracy
model_score = knn.score(X_test, y_test)
# save trained model
joblib.dump(knn, '/models/knn_model.pkl')
5. Predicting
The process of predicting digits on new images follows the same steps of singling out the digits illustrated in the training steps above and then simply applying k-NN’s predict function as shown below.
knn = joblib.load('/models/knn_model.pkl')def feature_extraction(image):
return hog(color.rgb2gray(image), orientations=8, pixels_per_cell=(10, 10), cells_per_block=(5, 5))def predict(df):
predict = knn.predict(df.reshape(1,-1))[0]
predict_proba = knn.predict_proba(df.reshape(1,-1))
return predict, predict_proba[0][predict]digits = []# load your image from file# extract featuress
hogs = list(map(lambda x: feature_extraction(x), digits))# apply k-NN model created in previous
predictions = list(map(lambda x: predict(x), hogs))
k-NN’s predict function returns a single digit value between 0 and 9 to denote the prediction class of the input image. K-NN’s predict_proba function returns the accuracy associated with each predicted class.
For instance, assume that we applied prediction on an image containing the digit “5”. An example of an output would be prediction=5 and predict_proba =[[0 0 0 0 0 .8 0 0 .2 0]] . This means that k-NN classified the image as “5” with 80% confidence and as “8” with 20% confidence.
Finally, predictions = list(map(lambda x: predict(x), hogs)) results in the following vector of tuples where each tuple represents the predicted class of each of the digits on the image with its associated prediction confidence. Any prediction that does not classify an input with 100% confidence will be presented to the user for manual correction as illustrated in the next section.
[
(5, 1.0), (1, 1.0), (9, 1.0), (2, 1.0), (1, 1.0), (2, 1.0), (4,1.0), (7, 1.0), (2, 1.0), (3, 1.0), (4, 1.0), (3, 1.0), (4, 1.0),
(4, 0.8), (0, 1.0)
]6. Presentation
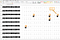
The last step was to present the result of the Machine Learning model in an excel file as shown below. For digits that were not predicted with 100% accuracy, I embedded the image of the expected digit below the actual prediction. This minor presentation tweak decreased the user’s time to fix the non accurate prediction by 80%. Furthermore, this activity is not daunting as it does not require significant mental effort. A user can scroll over the file in few minutes and visually matches the actual result to the expected result. Many of the predictions were actually false negative, hence the user did not have to make many corrections.

Reading List
Hamid, N. A., & Sjarif, N. N. A. (2017). Handwritten Recognition Using SVM, KNN and Neural Network. arXiv preprint arXiv:1702.00723.
Adrian Rosebrock’s blogs and books (https://www.pyimagesearch.com). Great computer vision resources and many posts on digits recognition.
Patel, I., Jagtap, V., & Kale, O. (2014). A Survey on Feature Extraction Methods for Handwritten Digits Recognition. International Journal of Computer Applications, 107(12).

