
Until recently, I wasn’t very familiar with using Typed Arrays because I tended to avoid the the black magic of working with binary data on the web.
But one doesn’t always have the luxury of choice. For example, when I began work on a music app that needed to run without a server, guess what time it became?
If you guessed “Typed Arrays time”, you’re a genius. Recall that Typed Arrays allow you to store and access raw binary data in JavaScript.
The app failed to generate valid music files and I had no idea why. I began to doubt whether it was even possible to do it completely in the browser.
Turns out, not only is it possible, it’s pretty straightforward! How often does that happen?
All you need to know is a little bit about how JavaScript stores strings, how those strings are represented as bytes, and what happens when you put those bytes into a file.
If debugging a broken binary file sounds daunting, I hope this story will remove some of the mystery so that you can confidently deal with any sort of binary data without resorting to a server.
The project I was working on was a music app to explore cyclic patterns which are often found in non-Western musical traditions.

This was for a class project so I wanted it to exist without having to worry about keeping a server running. If I could keep it as just a static JavaScript app I could host it on Github pages free and forever! So my partner and I resisted adding a backend server. Even when we wanted people to be able to save and load the patterns they created, we chose to save the state as a long base64 encoded string in the URL that could be shared to avoid using a database.
We were so close to having the whole thing running without a server now. The last thing we needed was a way to let the user download their creation as a MIDI file. If we could do that, then people could apply their own instruments to the notes, embed them in their own melodies or do their own further musical analysis. Our app would be much more useful then.
Generating MIDI files in JavaScript
The jsmidgen library seemed like it did exactly what we needed. It was a pure JavaScript implementation & it took the musical notes as inputs and created a MIDI file.
The problem was that all the examples they had were running in Nodejs. Here’s their example for creating a track with some notes and writing it to a file.
var fs = require('fs');
var Midi = require('jsmidgen');
var file = new Midi.File();
var track = new Midi.Track();
file.addTrack(track);
track.addNote(0, 'c4', 64);
track.addNote(0, 'd4', 64);
track.addNote(0, 'e4', 64);
track.addNote(0, 'f4', 64);
track.addNote(0, 'g4', 64);
track.addNote(0, 'a4', 64);
track.addNote(0, 'b4', 64);
track.addNote(0, 'c5', 64);
fs.writeFileSync('test.mid', file.toBytes(), 'binary');It didn’t look like it was made to be used on the client side, but the only thing I couldn’t do in the browser in that snippet was write to the filesystem. So as a workaround I used FileSaver.js to generate a download link for a Blob containing the binary data that jsmidgen returns.
Which looked like this:
http://jsmidgen.js
http://a%20data-href=
...
var file = new Midi.File();
var track = new Midi.Track();
file.addTrack(track);
track.addNote(0, 'c4', 64);
track.addNote(0, 'd4', 64);
track.addNote(0, 'e4', 64);
track.addNote(0, 'f4', 64);
track.addNote(0, 'g4', 64);
track.addNote(0, 'a4', 64);
track.addNote(0, 'b4', 64);
track.addNote(0, 'c5', 64);
var bytes = file.toBytes()
var blob = new Blob([bytes], {type:'audio/midi'})
saveAs(blob,"music.midi")I was relieved to see everything running with no errors and a download prompt popping up in my browser. This looked promising!
I double clicked the downloaded MIDI file and my heart sank.

Uh oh.
Debugging binary files
This was not what I thought would happen. I expected to get at least some sort of error that I could try and investigate. There were no warning or errors in the code. The generated file just…wasn’t working.
How do I even begin to debug a corrupted MIDI file? It could be missing some bytes, it could have some extra bytes, or it could just have the wrong bytes. I had no idea whether it was corrupted by the download library I was using, by the browser’s Blob interface, or something else entirely. I knew very little about the MIDI format, and learning how to tell why a given sequence of bytes was invalid seemed daunting.
At this point, it was really hard to resist adding in a server. It worked perfectly well in Node, and it would have been so easy to just send the data to a server to be processed and sent back. But we had made it this far without a server, and I wasn’t about to give up now.
I took a deep breath, rolled up my sleeves and decided to inspect the corrupted MIDI file in Sublime.
4d54 6864 0000 0006 0000 0001 00c2 804d 5472 6b00 0000 4400 c290 3c5a 40c2 803c 5a00 c290 3e5a 40c2 803e 5a00 c290 405a 40c2 8040 5a00 c290 415a 40c2 8041 5a00 c290 435a 40c2 8043 5a00 c290 455a 40c2 8045 5a00 c290 475a 40c2 8047 5a00 c290 485a 40c2 8048 5a00 c3bf 2f00
Looks like a perfectly fine binary-file-represented-as-hexadecimal to me. But of course we know something is wrong with it. Some part of this sequence doesn’t conform to how MIDI expects its byte sequence to look like. To compare, here is the file generated by the Node version of the code, which could be played correctly.
4d54 6864 0000 0006 0000 0001 0080 4d54 726b 0000 0044 0090 3c5a 4080 3c5a 0090 3e5a 4080 3e5a 0090 405a 4080 405a 0090 415a 4080 415a 0090 435a 4080 435a 0090 455a 4080 455a 0090 475a 4080 475a 0090 485a 4080 485a 00ff 2f00
It was certainly different, but not in a very systematic way. There were more bytes in the corrupted file, but the first few bytes in both files were identical! In fact, if you read it carefully, you’ll see that c2 is the only extra byte in the first line of the corrupted file.
This was even more mysterious. The corrupted file was mostly correct, but just slightly off; an extra byte here and there. Clearly if the output between running the code in Node and running it in the browser is different, then somewhere along the line the MIDI data changes. It would be nice if I could output the data at each step to see who was at fault, but the only way I had to look at this data was to print it out to the console (which just looked like garbled text when printed as a string) or by writing it to a file, which, for all I knew, might be the operation that corrupts the data!
It was like I couldn’t even look at the binary data without changing it. I was flying blind and I didn’t have any good evidence against any part of the code. So I just made a wild guess: Maybe jsmidgen has a bug and it doesn’t generate valid MIDI when running in the browser. I at least knew what the invalid byte was. Perhaps I could search for when c2was generated (or its decimal representation, 194) and trace through the logic that produced it.
Jsmidgen proven innocent
A couple of hours later, I found no flaws in the library. In fact, the number 194 never even occurred in the list of numbers generated by jsmidgen. It was ultimately a dead end search. I still had no idea why the data was being corrupted, but I did learn that jsmidgen creates a list of bytes just as a regular array of numbers and then calls String.fromCharCode on each number to convert it to a character. This is the final “bytes” value it returns. It’s just a string.
So if I wanted to see the raw bytes, all I had to do was convert each character in this string back into the character code that generated it.
var bytes = file.toBytes()
for(var i=0;i<bytes.length;i++){
console.log(bytes[i].charCodeAt(0))
}This officially absolved jsmidgen of any guilt. I could see that the same sequence of bytes I got in the browser was exactly the same as the one in Node! This was it! I had the correct output — it was just trapped within my application. Any attempt to send it to the outside world as a file resulted in this strange corrupted mess. I felt like the truth was in my grasp, but I was powerless to do anything about it. It was as if I was at a crime scene and knew who the killer was, and was yelling the answer at the top of my lungs but no one could hear me.
Could the mere act of converting these bytes to a JavaScript string change them? In principle it was possible if the numbers I was storing were outside of the range that strings could hold, and they were being truncated or overflowing somehow. But JavaScript strings are encoded using either UCS-2 or UTF-16 which more or less meant it represented values with 2 bytes, whereas MIDI stores each value in 1 byte. I verified this by ensuring that all values in the byte array generated by jsmidgen were below 256, so they definitely each fit in one byte, and nothing could possibly overflow.
Forcing an encoding
I couldn’t understand exactly why at the time, but it seemed like the different encoding schemes were part of the issue. JavaScript uses 2 bytes per value in its strings while MIDI used 1 byte.
If JavaScript strings stored 2 bytes for each character, why was I only seeing 1 byte per value in the resulting file? There should be empty 0 bytes next to each value.
Clearly since those weren’t present in the file, there must have been some sort of conversion happening! Could I force it to write out the original 2 bytes per value?
The answer was Typed Arrays. If I passed a typed array to the Blob, it wouldn’t attempt to do any conversion. So instead of:
var bytes = file.toBytes()
var blob = new Blob([bytes], {type:'audio/midi'})
saveAs(blob,"music.midi")I create an array that stores each value in 2 bytes (or 16 bits), and copy over all the values.
var bytes = file.toBytes() // remember, this is just a string
var u16 = new Uint16Array(bytes.length)
// Copy over all the values
for(var i=0;i<bytes.length;i++){
u16[i] = bytes[i].charCodeAt(0)
}
// Now we write the typed array to the Blob instead of the string
var blob = new Blob([u16], {type:'audio/midi'})
saveAs(blob,"music.midi")With that, I get a file that’s still corrupted, but has the correct values! Remember that the first line of the correct file had these values:
4d54 6864 0000 0006 0000 0001 0080 4d54
And my new file looked like:
4d00 5400 6800 6400 0000 0000 0000 0600 0000 0000 0000 0100 0000 8000 4d00 5400
If you remove the extra 00 after each byte, that’s exactly the same! All I had to do now was squeeze each of those 2 byte values into 1 byte. If I copied all the values into a Uint8Array instead of a Uint16Array it generated exactly the right file!
It finally worked! We didn’t need a server, we could now generate and download valid MIDI files!
But it was still quite baffling. To summarize: We had an original list of numbers that could each fit in 1 byte (they were all less than 256). We tried to put these numbers, encoded as a string, into a file with 1 byte each, and that led to extra bytes being added. To fix it, we put these numbers instead into a typed array, in 1 byte each, and the resulting file had the correct original list of bytes. It almost feels like we did nothing at all, as if just wrapping our data in a typed array magically fixed it!
It’s not magic
The secret lies in the Blob constructor. If you look closely, you’ll see that if you pass a string, it will get encoded as UTF-8. But still, why does that matter if all our values fit in one byte anyway?
My confusion came from thinking that a UTF-8 encoding just used 8 bits for each character (so only 1 byte) while UTF-16 used 16 bits for each character. So it was just like putting things in a Uint8Array and a Uint16Array respectively. This is not true. UTF-8 is a variable length encoding scheme that can represent much more than 256 characters (over a million in fact).
To see how this works, let’s try putting the simple string “Hello World” into a file. I highly encourage you to experiment with this yourself — here’s a file you can run locally to try this.
var sample_string = "Hello World!"
saveAs(new Blob([sample_string]),"output.txt")If we look at the resulting file using HexViewer we can see that each character is stored in one byte.
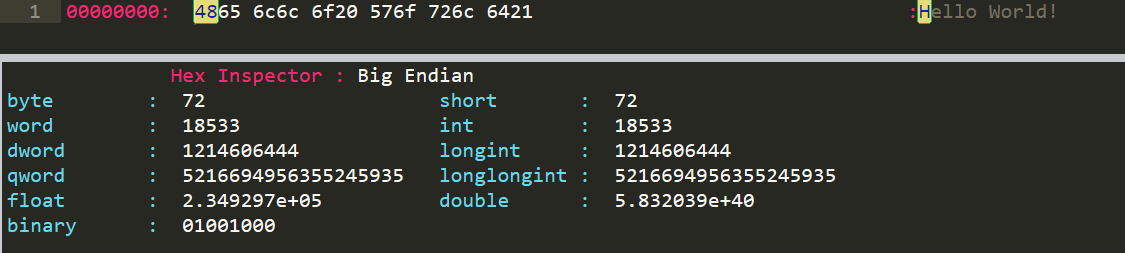
All these characters’ values are less than 256. Now what happens if we try to encode a string that has a character with an associated value that can’t fit in one byte? Let’s try to put “Hello✨World!” in a file. The “✨” character has a Unicode value of 10,024.
var sample_string = "Hello" + String.fromCharCode(10024) + "World!" saveAs(new Blob([sample_string]),"output.txt")
Al the other characters are still stored in 1 byte, but this new character takes up 3 bytes!

If you convert 10024 to binary, you get a 14 digit number, so we really only need 2 bytes to store it. But let’s look at how UTF-8 does it.
The 3 bytes it uses for “✨” are e2 9c a8. In binary, that’s:
11100010 10011100 10101000
The table on this page describes how to decode UTF-8. It says that if this character is encoded in 3 bytes, then we take:
- The last 4 bits of the first byte,
- the last 6 bits of the second byte,
- and the last 6 bits of the third byte.
This leaves us with:
0010 011100 101000
Which if you convert to decimal turns out to be 10024! Since 10024 fits in 2 bytes, we could alternatively have just stored every character in 2 bytes.
var sample_string = "Hello" + String.fromCharCode(10024) + "World!"
var bytes = []
for(var i = 0;i < sample_string.length; i++){
bytes.push(sample_string[i].charCodeAt(0))
}
var u16 = new Uint16Array(bytes)
saveAs(new Blob([u16]),"output.txt")And we get:

Which is definitely simpler (to recover the original value, you just concatenate each pair of bytes, with the second byte on the left) but you can see how it wastes a lot more space if most of your values fall in the English alphabet range.
Solving the mystery
So where did the mysterious c2 come from? If you look back to the page that describes UTF-8, you’ll notice that it uses 1 byte for anything under 127, and 2 bytes after that. So here’s the first line of the original corrupted MIDI again:
4d54 6864 0000 0006 0000 0001 00c2 804d
There shouldn’t be a c2 there. It should just be 80 . Remember that this is in hexadecimal, so 80 in hex is 128 in base 10. Let’s try to decode this the same way we did earlier. The two bytes c2 80 in binary are:
11000010 10000000
For two bytes, the UTF-8 decoding table says we remove the first 3 bits of the first byte, and the first 2 bits of the second byte, leaving us with:
00010000000
Which is 128. So even though the value 128 fits perfectly fine in 1 byte, the UTF-8 encoding stores it in 2 bytes (do you see why it can’t store 128 in 1 byte?) The only reason we know that those 2 bytes represent together the single value 128 instead of the two values 194 and 128 is only because we know it was encoded as UTF-8 (which is why it’s always crucial to declare the encoding of your files). But the MIDI decoder doesn’t know that. It kept reading it as one byte at a time, as a 194 followed by a 128, and that’s why the file was corrupted.
Conclusion
I hope you found this dive into binary data and encoding illuminating! I think it’s empowering to know that you can have this much control over how your data is stored in JavaScript with typed arrays, and sometimes you need this control to make things work completely in the browser.
200’s only  Monitor failed and slow network requests in production
Monitor failed and slow network requests in production
Deploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third party services are successful, try LogRocket.  https://logrocket.com/signup/
https://logrocket.com/signup/LogRocket is like a DVR for web and mobile apps, recording literally everything that happens while a user interacts with your app. Instead of guessing why problems happen, you can aggregate and report on problematic network requests to quickly understand the root cause.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.