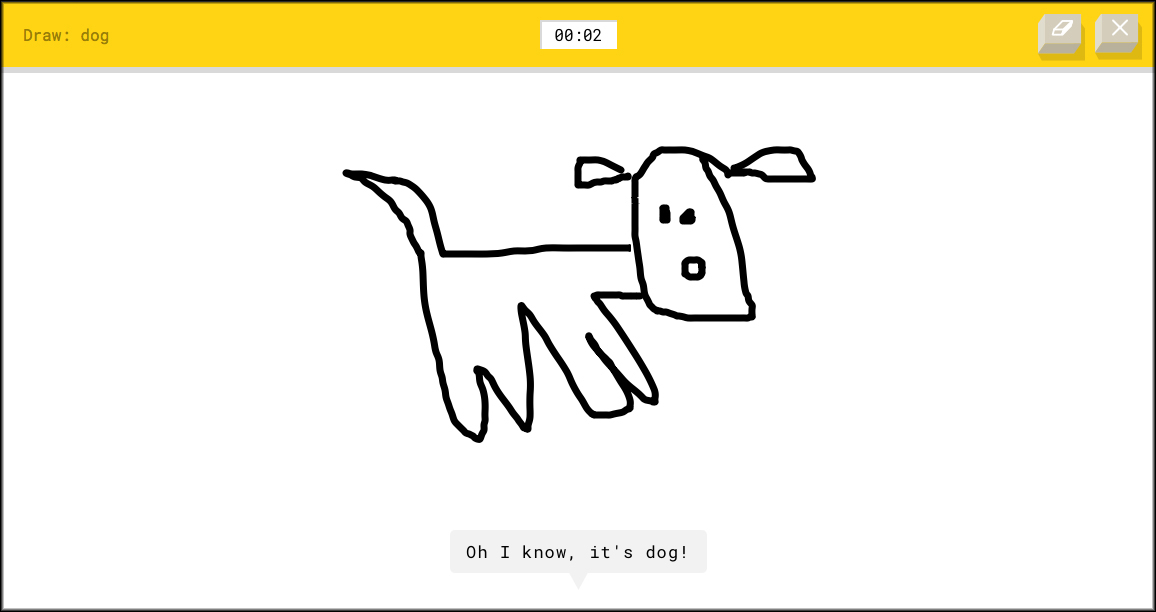
Jo flere elendige skisser folk kaster på Quick, Draw!, jo flinkere blir tjenesten til å gjette hva det skal forestille.
Vi kan virkelig IKKE tegne
Vi i NRKbeta kan mange ting – å tegne er dessverre ikke en av dem.
Likevel måtte vi prøve om vi klarte å lage gjenkjennelige skisser av tingene «Quick, Draw!» ba oss tegne på mobilskjermen. Magisk nok; vi klarte rundt 2 av 3, selv om nærmest fotorealistiske tegninger som Ståles flaggermus forvirret mekanikken.
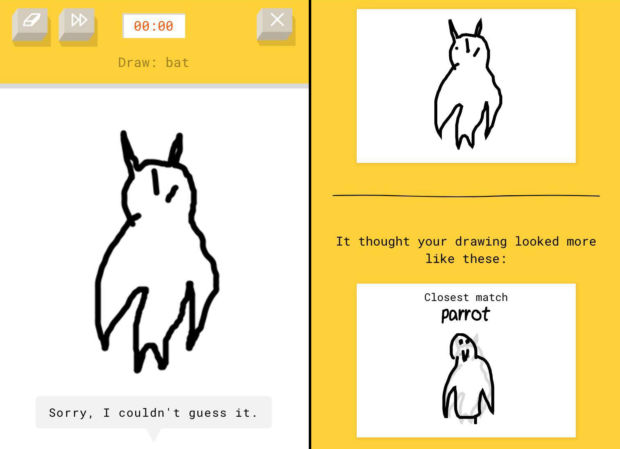
Nevralt nett
Tjenesten er et av prosjektene i maskinlærings-prosjektet A.I. Experiments, og bruker såkalt nevralt nettverk-teknologi for å sammenlikne ting. At vi i NRKbeta ikke er planetens dyktigste skissetegnere blir dermed lettere å håndtere for teknologien – for den kan sammenlikne med alle de andre dårlige skissene folk tegner.
Utfordringene
Noe av det som var vanskeligst, var når vi skulle illustrere konsepter, mer enn konkrete fysiske ting – som for eksempel animal migration; dyretrekk.

Heldigvis er det tydeligvis folk som har tenkt på samme måten som oss tidligere, så klumsete forsøk #2 på å tegne et gåsetrekk fikk godkjent-stempel – selv om det tydeligvis også liknet en strand.
Og HVORDANIALLVERDEN tegner man en albu? Vi skjønner godt hvorfor dette var en oppgave som kom igjen og igjen – den var tydelig IKKE fornøyd med resultatet.
Men kalkulator? Hallo?

Hva kommer det ut av det?
Dette opplegget med å lage noe som på overflaten er et morsomt spill, men som under panseret også lærer opp et nettverk til å forstå folks skisser kan jo i prinsippet brukes til mer enn å lage en jukseapp for brettspillet Fantasi. Man kan både se for seg at det går an å lage brukergrensesnitt som baserer seg på skissing (selv om vi ikke i farten kommer på i hvilke tilfeller det er mer effektivt enn alternativene) og at man kan få et bilde av hvilken felles indre ikonografi vi mennesker har for ulike konsepter. Og det virker som det (akkurat som i Fantasi) ikke er lov å hjelpe til med tekst:

…eller kanskje vi ikke har skjønt verdien av dette i det hele tatt, og burde tatt oss tiden til å lese litt om tankene som ligger bak. Men vi hadde ikke så mange minuttene til å leke med dette på en ellers travel dag.
Uansett: Her kan du teste Quick, Draw! Hvis du klarer å legge det fra deg etter én runde har du enten mer stålvilje enn oss, ellerer utrolig lite leken (eller enda dårligere til å tegne på mobilen enn vi er).

Men:
a) hva tror dere er de nyttigste tingene som kan komme ut av dette prosjektet
b) har dere eksempler på ting som likner som vi har gått glipp av
c) … og var det ikke ganske gøy?


Den forteller deg jo hva du skal tegne.
«Tegn et vinglass,» sier den og gjetter det etter to streker. Men tegner du vinglass igjen når den ber deg tegne noe annet skjønner den ingenting.
Det er vel snakk om å trene opp den kunstige intelligensen med såkalt «Big Data». Jo mer data som kommer inn, uansett hva, jo bedre blir intelligensen?
Å lære å lære, forstå konsepter, kunne resonnere seg frem til en ting ved å se på noe annet…
Nå er tydelig vis ikke hele internetts bildebibliotek stort nok lenger, så de vil
Morsomt, men litt nyttesløst.. Dette prosjektet vil aldri «komme i mål» i den forstand at denne teknologien ikke vil bli like god på gjenkjennelse som vi er. Bedre enn nå vil den sikkert bli, men den vil alltid ta feil innimellom. Dette fordi denne teknologien verken ser, gjenkjenner eller forstår noe som helst av hva vi tegner eller hva den spør etter. Dette er grovt sagt bare avansert sannsynlighetsregning, som etteraper egenskaper vi kjenner fra vår egen hjerne. Når hjernen vår gjør slike ting, ligger det imidlertid helt andre systemer i bunn. Dette er kort sagt et forsøk på å lage eplekake av pærer.
Dette er veldig forskjellig frå bildegjenkjenning slik Google, Bing og facebook driver med i stor skala. Når eg vart bedt om å tegne ein ambulanse gjetta den «riktig» sjølv om eg ikkje hadde kome lenger enn til å teikne ein vanleg bil. Den greide det fordi den kunne velge mellom eit lite antal forhåndsdefinerte kategoriar. Programmet avslørte her at «bil» ikkje var lagt inn som kategori, sikkert fordi nettverket sleit med å skille mellom bil og ambulanse. Slik sminker ein statistikken.
Moderne bildegjenkjenning derimot, bygger opp kategoriane sine sjølv, ser at biler består av hjul og dører, at ambulanse er ein type bil, kan gjenkjenne same bil frå forskjellige vinklar og lysforhold osv. Vil ein ha ei smaksprøve på kva bildegjenkjenning får til i dag, prøv heller Microsofts computer vision API: https://www.microsoft.com/cognitive-services/en-us/computer-vision-api
Forskjellen på a) at et menneske forteller systemet hvilke kategorier det skal forholde seg til og b) at et menneske forteller systemet at det skal definere kategorier selv er vel strengt tatt ikke særlig stor. Uten hjelp fra menneskets intelligens hadde ikke systemet ant at det måtte forholde seg til kategorier i det hele tatt…
B) relatert stoff til deg som ønsker å programmere litt AI/Maskinlæring:
https://vimeo.com/search?q=maskinl%C3%A6ring
takk 🙂